Functional Unblinding, Expectancy Bias, and What It Means for Psychedelic Trial Design
Published
February 23, 2026
Part 2 of 2 on Compass Pathways’ COMP360 psilocybin program for treatment-resistant depression. Part 1 examined what “clinically meaningful” means when applied to trial results. This note asks whether we can trust the blind in psychedelic trials—and what it means for the numbers we interpreted in Part 1. This series is a companion to the Experimental Designs chapter of Global Health Research in Practice.
In this episode of Research Notes, Eric talks with Dr. Gabe Loewinger of the National Institute of Mental Health about a core challenge in psychedelic clinical trials: participants often know whether they received the treatment.
There is no placebo experience for a 4–6 hour journey through the architecture of your own consciousness. Participants figure this out.
In the psychedelic trials that have formally assessed blinding, more than 9 out of 10 participants in the active arm correctly identified that they received the drug. Not because of a labeling error or a protocol deviation, but because a high-dose psychedelic produces vivid perceptual changes, emotional intensity, and a sense of expanded meaning that the control arm simply does not experience. Within the hour, the blinders are off.
This is functional unblinding—when the intervention’s experiential signature is so distinctive that participants can reliably identify their assignment regardless of how carefully the trial is designed. It presents a fundamental inference challenge: if participants know what they received, how do we separate what the drug does from what believing you received the drug does? In this note, we consider that question in the context of Compass Pathways’ psilocybin program for treatment-resistant depression.
The Logic of Blinding
Blinding exists to break the link between treatment assignment and outcome reporting. If participants know which arm they are in, that knowledge can shape how they experience and report their symptoms. Blinding keeps the comparison fair by ensuring that both arms are equally ignorant.
But blinding is not always possible. In global health research, many interventions are impossible to mask—you cannot create a placebo cash transfer or a sham bed net. Psychotherapy trials face the same constraint: participants always know whether they are receiving CBT or sitting on a waitlist. These trials produce actionable evidence, but the interpretive challenge is acknowledged. Decades of psychotherapy research have grappled with separating specific therapeutic ingredients from nonspecific effects—the expectation of improvement, the therapeutic relationship, the act of showing up.
Drug trials with subjective endpoints usually avoid this problem through blinding. When the outcome is a self-reported measure of inner experience—how sad do you feel, how well did you sleep, how pessimistic are your thoughts—knowing what you received can directly shape how you answer. Identical-looking pills make it possible to keep both arms equally ignorant, and the regulatory system is built on this assumption.
The question is what happens when a drug trial cannot maintain that blind—not because of a design failure, but because the drug announces itself. You inherit the interpretive challenges of psychotherapy research, but within a framework that assumes they have been designed away.
Unblinding in Psychedelic Trials
Unblinding means participants know (or strongly suspect) which arm they are in. It’s not clear how often it happens because most psychedelic RCTs do not report on it. A 2024 systematic review found that 71% of psychedelic RCTs omit blinding assessments entirely. Among those that do assess blinding, results are discouraging: a separate review found that 78% demonstrate “poor” masking. The MDMA trials for PTSD—the most prominent psychedelic program to reach regulatory review—illustrate what “poor masking” looks like in practice.
Show code
blinding <-tribble(~trial, ~arm, ~guess_correct_pct, ~arm_type,"MDMA PTSD Phase 3, MAPP2\n(Mitchell et al., 2023)", "MDMA", 94, "Active dose","MDMA PTSD Phase 3, MAPP2\n(Mitchell et al., 2023)", "Placebo", 75, "Control/low dose","MDMA PTSD Phase 3, MAPP1\n(Mitchell et al., 2021)", "MDMA", 96, "Active dose","MDMA PTSD Phase 3, MAPP1\n(Mitchell et al., 2021)", "Placebo", 84, "Control/low dose")# Build dumbbell ranges per trialtrial_ranges <- blinding |>group_by(trial) |>summarise(min_pct =min(guess_correct_pct),max_pct =max(guess_correct_pct),.groups ="drop" )# Order trials by max guess ratetrial_order <- trial_ranges |>arrange(max_pct) |>pull(trial)blinding <- blinding |>mutate(trial =factor(trial, levels = trial_order))trial_ranges <- trial_ranges |>mutate(trial =factor(trial, levels = trial_order))ggplot() +geom_vline(xintercept =50, linetype ="dashed", color ="grey50") +# Dumbbell segments connecting arms within each trialgeom_segment(data = trial_ranges,aes(x = min_pct, xend = max_pct, y = trial, yend = trial),color ="grey60", linewidth =1.5 ) +# Points for each armgeom_point(data = blinding,aes(x = guess_correct_pct, y = trial, color = arm_type),size =5 ) +# Arm labelsgeom_text(data = blinding,aes(x = guess_correct_pct, y = trial, label = arm),vjust =-1.2, size =4.5, color ="grey30" ) +annotate("text", x =50, y =0.55, label ="Chance (50%)",hjust =-0.05, color ="grey50", size =4.5, fontface ="italic" ) +scale_color_manual(values =c("Active dose"= ghr_blue, "Control/low dose"= ghr_orange),name =NULL ) +scale_x_continuous(limits =c(45, 105),breaks =seq(50, 100, 10),labels =function(x) paste0(x, "%") ) +labs(title ="Most Participants Guess Correctly",subtitle ="Correct guess rates by trial arm",x =NULL,y =NULL ) +theme(legend.position ="none",panel.grid.major.y =element_blank(),panel.grid.minor =element_blank(),plot.title =element_text(face ="bold", size =22, hjust =0),plot.title.position ="plot",plot.subtitle =element_text(color ="grey40", size =17, hjust =0),axis.text.y =element_text(size =15),axis.text.x =element_text(size =14) )
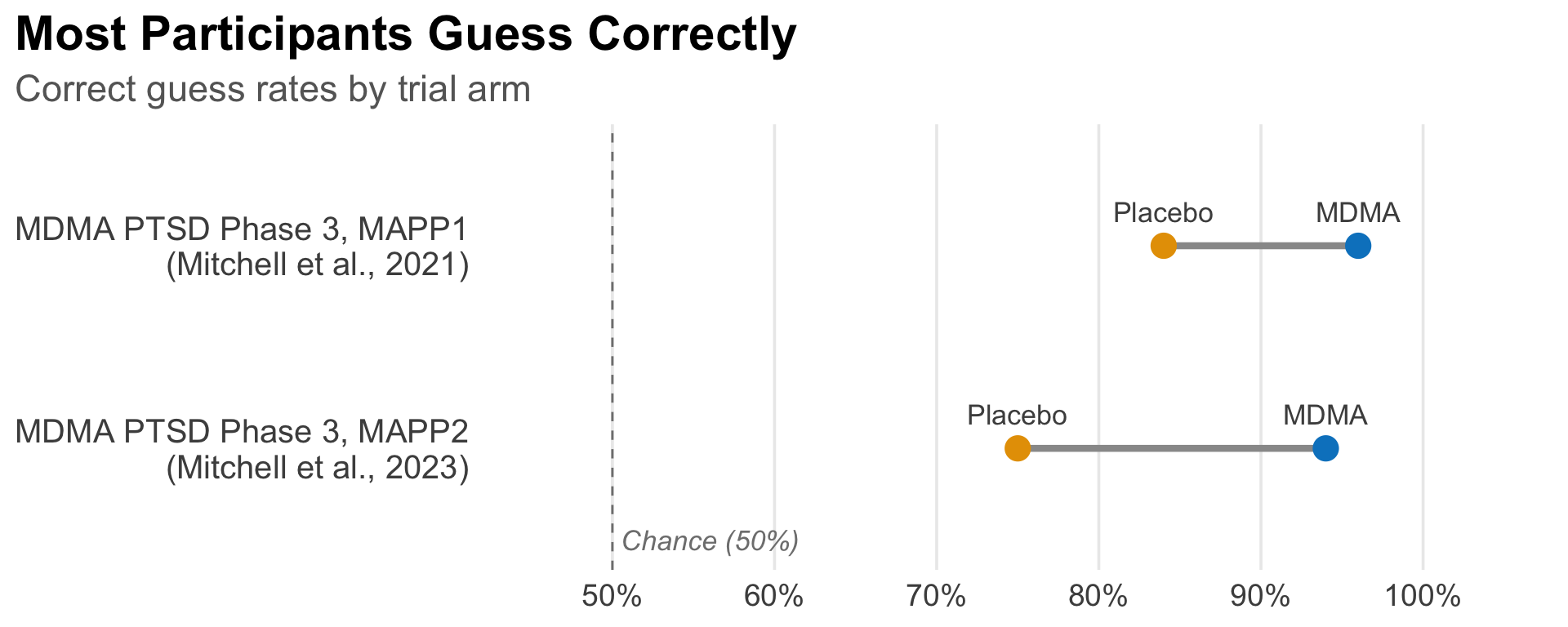
Correct treatment-arm guessing rates in MDMA trials that formally assessed blinding. Each bar spans from the placebo arm to the MDMA arm within the same trial. Data from Mitchell et al. (2023, MAPP2 formal blinding survey) and Mitchell et al. (2021, MAPP1 derived from unblinding data).
In the MAPP2 Phase 3 MDMA trial—the only MAPS study with a formal blinding survey—94% of participants in the MDMA arm correctly identified their assignment, and 75% of the placebo arm did the same (Mitchell et al., 2023). The earlier MAPP1 trial showed a similar pattern, with roughly 96% and 84% correct guessing in the MDMA and placebo arms, respectively (Mitchell et al., 2021).1
These are not marginal failures of blinding. They represent near-complete loss of masking. And the pattern is consistent: active-dose arms guess at rates far exceeding chance, while control arms also guess above chance—suggesting that the absence of a psychedelic experience is itself informative.
Does Unblinding Matter?
But does it matter? Unblinding is not the same as bias. It creates the conditions for bias—particularly when the outcome is a self-reported measure of subjective experience. What we really need to know is the degree and effect of expectancy: whether knowledge of one’s assignment shapes their experience and reporting. Unblinding and expectancy are related but separable. A participant who correctly guesses their assignment may or may not adjust their symptom reporting as a result. The question is how much it matters for interpreting the numbers.
Unfortunately, almost no psychedelic trial has reported on expectancy.2
In the absence of direct expectancy data, we can still think about the bounds of what could be happening. Consider a thought exercise: if some fraction of the observed drug-placebo difference is driven by differential expectancy rather than pharmacology, how large would that fraction have to be before the result is no longer clinically meaningful?
The logic is straightforward. If the observed difference is a composite of pharmacology and expectancy, we can discount the observed effect by an assumed expectancy fraction and check whether the adjusted result remains clinically meaningful.3
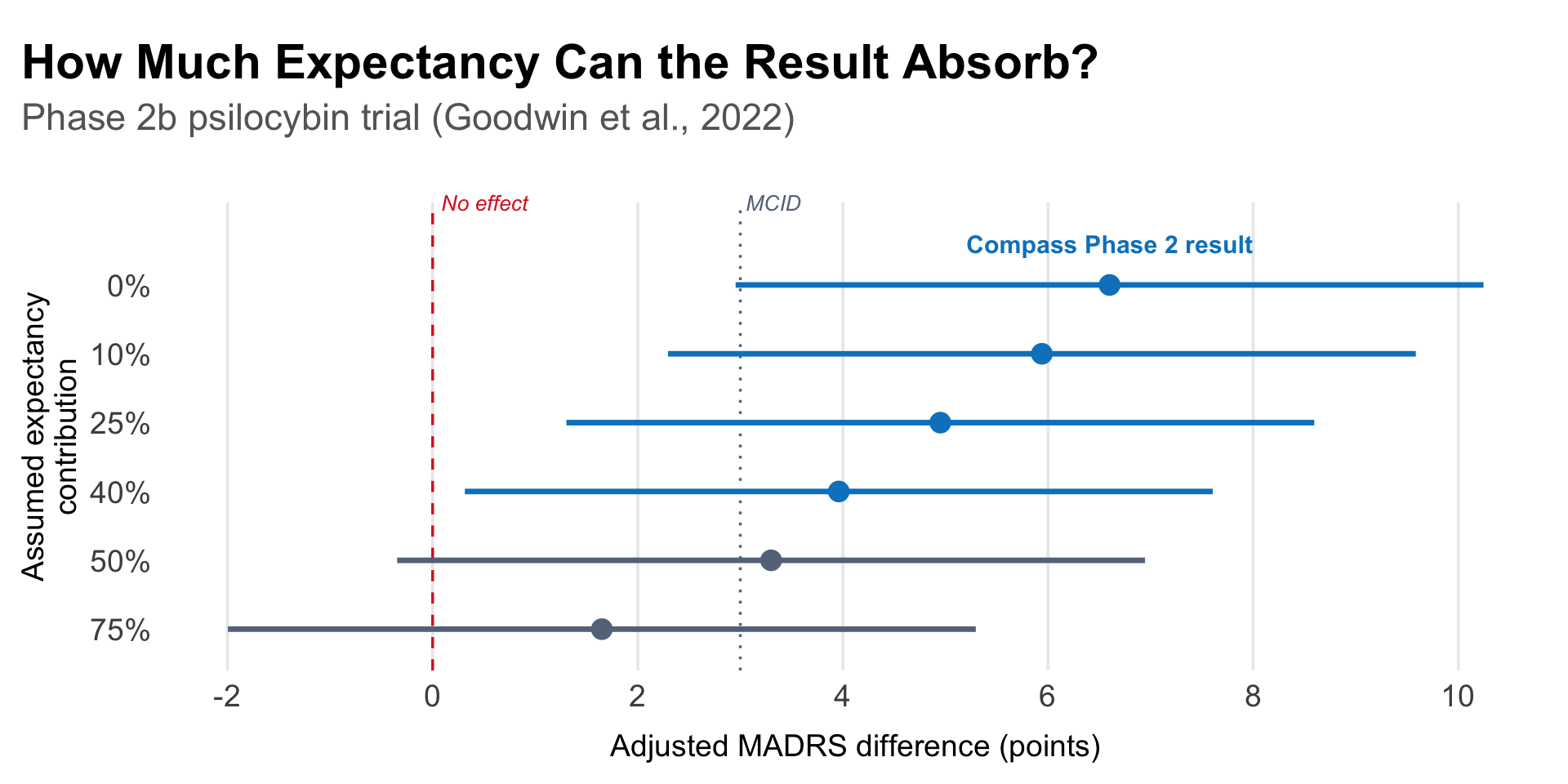
We can apply this logic to the Compass Phase 2b trial (Goodwin et al., 2022), the trial we examined in Part 1. It randomized 233 participants with treatment-resistant depression to 25 mg, 10 mg, or 1 mg psilocybin and found a 6.6-point MADRS advantage for the 25 mg dose over 1 mg (95% CI: 2.9 to 10.2, p < 0.001).
Show code
# Phase 2b: Goodwin et al. (NEJM 2022)# Δ = 6.6 (25mg vs 1mg), 95% CI [2.9, 10.2]# SE = (10.2 - 2.9) / (2 * 1.96) = 1.86delta_obs <-6.6se <-1.86sensitivity <-tibble(f =c(0, 0.10, 0.25, 0.40, 0.50, 0.75),label =paste0(f *100, "%")) |>mutate(adj_delta = delta_obs * (1- f),ci_low = adj_delta -1.96* se,ci_high = adj_delta +1.96* se,z = adj_delta / se,p =2*pnorm(-abs(z)),significant = p <0.05,label =factor(label, levels =rev(paste0(c(0, 10, 25, 40, 50, 75), "%"))) )# Get the point estimate for the 0% row to position the labelobs_delta <- sensitivity |>filter(f ==0) |>pull(adj_delta)ggplot(sensitivity, aes(x = adj_delta, y = label)) +# Reference linesgeom_vline(xintercept =0, linetype ="dashed", color = ghr_red,linewidth =0.6) +geom_vline(xintercept =3, linetype ="dotted", color = ghr_slate,linewidth =0.6) +# CI segmentsgeom_segment(aes(x = ci_low, xend = ci_high, yend = label,color = significant),linewidth =1.2) +# Point estimatesgeom_point(aes(color = significant), size =4) +# Compass Phase 2 label above the 0% rowannotate("text", x = obs_delta, y =6.6, label ="Compass Phase 2 result",color = ghr_blue, size =4, fontface ="bold") +# Reference line annotationsannotate("text", x =0, y =7.2, label ="No effect",color = ghr_red, size =3.5, fontface ="italic",hjust =-0.1) +annotate("text", x =3, y =7.2, label ="MCID",color = ghr_slate, size =3.5, fontface ="italic",hjust =-0.1) +scale_color_manual(values =c("TRUE"= ghr_blue, "FALSE"= ghr_slate),guide ="none" ) +scale_x_continuous(breaks =seq(-2, 10, 2)) +coord_cartesian(clip ="off") +labs(title ="How Much Expectancy Can the Result Absorb?",subtitle ="Phase 2b psilocybin trial (Goodwin et al., 2022)",x ="Adjusted MADRS difference (points)",y ="Assumed expectancy\ncontribution" ) +theme(panel.grid.major.y =element_blank(),panel.grid.minor =element_blank(),plot.title =element_text(face ="bold", size =22, hjust =0),plot.title.position ="plot",plot.subtitle =element_text(color ="grey40", size =17, hjust =0,margin =margin(b =30)),axis.text =element_text(size =14),axis.title =element_text(size =14),axis.title.x =element_text(margin =margin(t =10)),axis.title.y =element_text(angle =90),plot.margin =margin(t =20, r =10, b =10, l =10) )
Sensitivity of the Phase 2b psilocybin result to assumed expectancy contribution. Each row shows the adjusted MADRS drug-placebo difference and 95% CI after discounting the observed effect by the stated percentage. Dashed lines mark no effect (0) and the commonly cited minimum clinically important difference (MCID ≈ 3 points). Based on Goodwin et al. (2022): observed Δ = 6.6, SE = 1.86.
The adjusted effect drops below an MCID of ~3 MADRS points around 55%—meaning you would have to believe that more than half of the observed 6.6-point difference is driven by differential expectancy before the Phase 2b result fails to clear the bar for clinical relevance.4 Statistical significance is lost somewhat earlier, around 45%. Whether these thresholds feel reassuring or alarming depends on your prior beliefs about the magnitude of expectancy bias—beliefs that are themselves poorly constrained by available data.
Is subtraction even the right question? This sensitivity analysis assumes pharmacology and expectancy are additive. Szigeti and Heifets (2024) raise the possibility of a drug × expectancy interaction: the molecule might work through a mechanism that requires the patient’s awareness. If so, “pharmacology” and “expectancy” are not separable line items—they are entangled, and subtraction gives the wrong answer. Testing this would require a balanced placebo design—a 2×2 crossing of actual treatment with perceived treatment—but such designs rely on deception, which is ethically problematic and practically infeasible when the drug produces an unmistakable 4–6 hour altered state. The result is an interpretive gap that no available trial design can fully close.
The Methods Toolbox
Several design strategies have been proposed to address the blinding problem.
Active placebos give the control arm something that produces noticeable effects, so participants cannot easily distinguish treatment from control. Niacin has been the most common choice because it produces a flushing sensation, but its effects last roughly 30–60 minutes compared to psilocybin’s 4–6 hour altered state. Aday et al. (2025) proposed criteria for an “ideal” active placebo and evaluated candidates including dextromethorphan (DXM), delta-9-THC, and diphenhydramine. None is a perfect match, but DXM’s dissociative effects and multi-hour duration make it the strongest candidate for future trials.
Dose-response designs compare across doses rather than drug to placebo. The advantage is that all participants receive “something,” which may reduce differential expectancy, and a dose-response gradient is harder to explain by belief alone. The tradeoff is that if the low dose is itself pharmacologically active, the observed difference between arms is compressed relative to what a true placebo comparison might show.
These design strategies help, but Loewinger et al. (2025, preprint) argue in a pre-print they may not resolve the core problem. Expectancy itself may exhibit a dose-response relationship with the psychedelic dose: higher doses produce more vivid experiences, which produce higher expectations of improvement. If so, the dose-response gradient in the outcome could be mediated through expectancy rather than pharmacology, and neither active placebos nor low-dose comparators fully close the gap.
What about measuring expectancy and adjusting for it? The FDA’s 2023 draft guidance suggests that blinding questionnaires “can be helpful” for evaluating the impact of functional unblinding. But Loewinger et al. caution that the obvious analytical approaches are more dangerous than they appear.
To see why, consider the causal structure of a functionally unmasked trial.
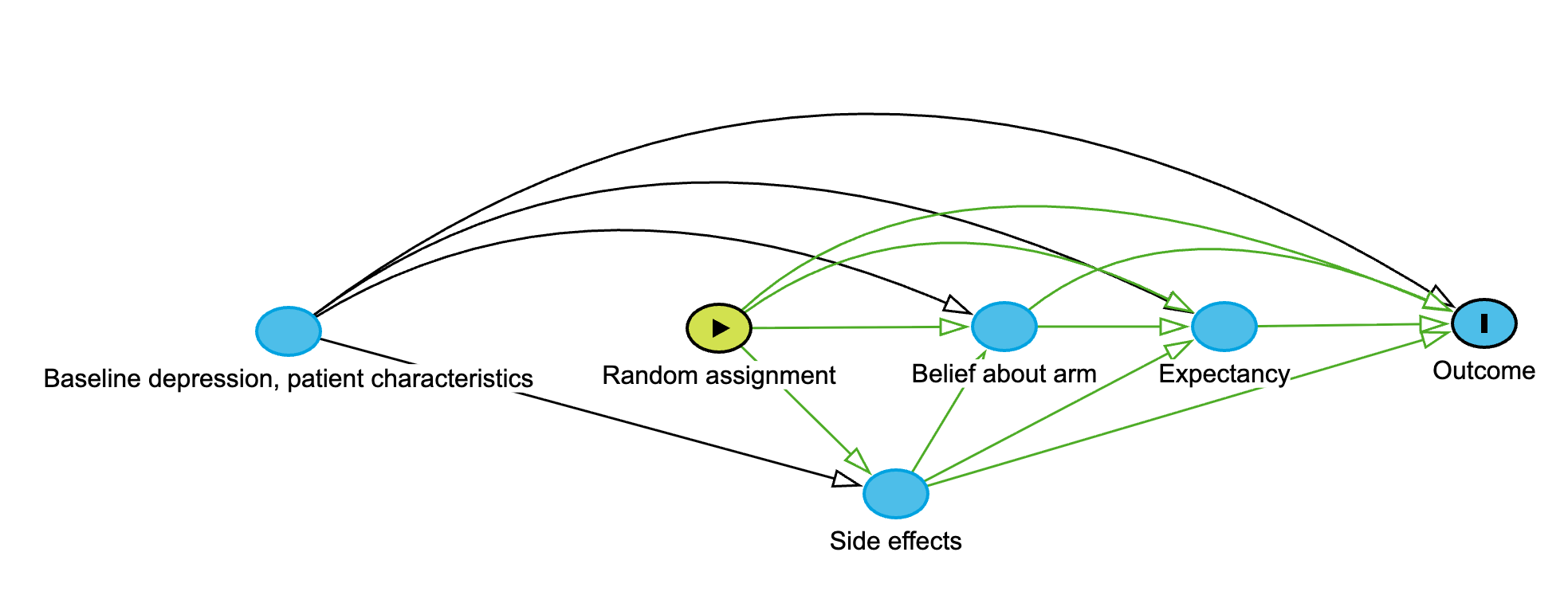
Causal structure of a psychedelic trial with functional unmasking, adapted from Loewinger et al. (2025). Random assignment is exogenous (no arrows in). Black arcs show the direct causal effects of baseline covariates and random assignment on the outcome. Green arrows trace the mediated pathways: assignment causes side effects, which shape belief about arm, which shapes expectancy, which affects the outcome. Belief and expectancy are post-treatment mediators, not confounders. Stratifying on them introduces collider bias. Interactive version.
Because expectancy is caused by treatment—participants figure out what they received from the side effects—it sits on the causal pathway between random assignment and outcome, making it a mediator, not a confounder. Stratifying results by post-treatment belief about arm (e.g., comparing treatment effects among those who guessed correctly vs. incorrectly) introduces collider bias: in simulations, Loewinger et al. show this can make a genuinely beneficial treatment appear harmful. This is not a theoretical curiosity—it is a direct critique of the kind of stratified analysis that Lykos presented to the FDA advisory committee.
If simple stratification is misleading, what should analysts do instead? Loewinger et al. propose framing the question as a formal mediation problem and targeting the controlled direct effect (CDE): the treatment effect you would observe if everyone had the same level of expectancy. Estimating the CDE requires measuring not expectancy itself but its common causes—pre-treatment covariates like baseline depression, patient characteristics, and media exposure (“hype”)—and applying semiparametric causal inference methods rather than conventional regression adjustment.5 The implication is not that trials are useless, but that interpreting their results requires more sophisticated methods than a subgroup comparison or a p-value provides.
The Regulatory Question
How do regulators think about blinding? The FDA’s framework assumes that a drug’s effect is primarily biological—a molecule acting on a target—and that blinding is the tool that separates pharmacology from everything else. When blinding works, the drug-placebo difference is interpretable. When it fails, the difference could reflect pharmacology, expectancy, or some mixture, and the agency has no way to tell how much of each. Two pieces of recent regulatory history show how seriously the agency takes this problem.
The 2023 draft guidance. The FDA’s draft guidance on psychedelic clinical investigations flagged functional unblinding as a core concern, suggested that blinding questionnaires “can be helpful” for evaluating its impact, noted that psychotherapy components increase the potential for expectancy bias, and raised factorial designs as a way to disentangle drug and therapy effects. The language was measured—“can be helpful,” “may be useful”—but the signal was clear: the agency wants sponsors to quantify the problem, not just acknowledge it as a limitation.
The Lykos MDMA vote. On June 4, 2024, the FDA’s Psychopharmacologic Drugs Advisory Committee voted 2–9 against the effectiveness of MDMA-assisted therapy for PTSD—despite large effect sizes in two Phase 3 trials. The committee’s concerns spanned data integrity, safety characterization, the role of psychotherapy, and the durability of effects, but interpretability was central: the FDA’s own discussion questions asked the committee to weigh “the potential impact of functional unblinding on interpretability of efficacy results.” Over 90% of MDMA participants correctly guessed their assignment, and committee members questioned whether the drug-placebo difference reflected pharmacology or differential expectancy. The FDA issued a Complete Response Letter in August 2024, requesting an additional Phase 3 trial.
Roseman (2025) framed the vote as reflecting paradigmatic tensions: the regulatory system assumes drug effects are primarily biological, with context as noise to be controlled. But psychedelic-assisted therapy may work precisely because context—the therapeutic setting, the preparation, the integration—interacts with the pharmacological experience. If so, the framework built for evaluating SSRIs may not straightforwardly apply.
The Compass Case
This is the landscape Compass Pathways is navigating with its Phase 3 psilocybin program for treatment-resistant depression. Their approach is deliberate: two trials with complementary control strategies. COMP005 compares 25 mg psilocybin to inert placebo, giving the FDA what it traditionally requires. COMP006 compares 25 mg to a 1 mg active comparator—what Chief Medical Officer Guy Goodwin called “the low expectancy response arm” on the company’s results call—designed to reduce unblinding by ensuring all participants receive some form of the drug.
The strategy has a tradeoff that Goodwin acknowledged openly. The Phase 3 overlay showed that the 1 mg arm produced numerically greater improvement than inert placebo, confirming it is pharmacologically active. This means the drug-placebo difference in COMP006 (3.8 points) is compressed relative to what a true placebo comparison might show—a cost Compass accepted in exchange for a more interpretable efficacy signal. Both trials used remote, centralized MADRS raters who were blinded to assignment, reducing rater-level bias even when participant-level blinding fails.
Goodwin confirmed that the Phase 3 trials collected both pre-treatment expectancy measures and post-treatment blinding assessments, including guessing accuracy and confidence. These data have not yet been published. When they are, the analytical choices will matter as much as the numbers: as Loewinger et al. argue, naive adjustment for expectancy or stratification by guessing accuracy can introduce more bias than it resolves. Whether Compass applies formal causal methods—targeting the controlled direct effect rather than conditioning on post-treatment variables—will determine whether the analysis clarifies or obscures the picture.
What to Watch For
The Compass psilocybin program is heading toward regulatory review, likely in late 2026 or 2027. Compass confirmed they collected pre-treatment expectancy measures, post-treatment guessing accuracy, and confidence ratings across both Phase 3 trials—potentially a more comprehensive set of blinding and expectancy data than any prior psychedelic program has reported. Three things will shape what these data mean:
What the blinding data show. The guessing rates alone will tell us whether the dose-response design in COMP006 preserved the blind better than the placebo-controlled COMP005. If the 1 mg active comparator reduced correct guessing relative to inert placebo, it validates the design rationale. If guessing rates are similarly high across both trials, the dose-response design did not solve the blinding problem—it just changed the comparator.
How the data are analyzed. This is where the Loewinger et al. critique becomes practical. If Compass stratifies results by guessing accuracy or conditions on post-treatment belief in a conventional regression, the analysis risks the collider bias described above. If they instead target the controlled direct effect using the pre-treatment covariates they collected, they might be the first psychedelic program to apply formal causal methods to the unblinding problem.
Whether the Lykos precedent holds. The MDMA rejection established that blinding concerns can override large effect sizes. If the FDA applies the same standard to psilocybin, Compass may need more than two positive trials. It will need to show that the analytical approach to expectancy is rigorous—not just that the data were collected, but that the right causal question was asked.
Footnotes
The Bogenschutz et al. psilocybin trial for alcohol use disorder (2022) reported an aggregate correct-guess rate of ~94% across arms, despite using diphenhydramine as an active placebo. Most psychedelic trials central to the current regulatory discussion—including the Compass Phase 2b (Goodwin et al., 2022) and the Raison et al. JAMA psilocybin trial (Raison et al., 2023)—did not formally assess blinding. Both acknowledged functional unblinding as a limitation.↩︎
A 2024 systematic review found that 71% of psychedelic RCTs omit blinding assessments entirely, and virtually none measure pre-treatment expectancy using validated instruments. The one macrodose trial that has published expectancy data—a secondary analysis of the psilocybin vs. escitalopram trial (Szigeti et al., 2024)—found that psilocybin expectancy did not predict psilocybin outcomes, while escitalopram expectancy did predict escitalopram outcomes. Muthukumaraswamy et al. (2021) and Aday et al. (2022) have both called for routine expectancy measurement; the MAPS MDMA trials collected none, and Compass confirmed on its Phase 3 results call that it collected pre-treatment expectancy measures but has not yet published them.↩︎
This is a standard sensitivity analysis, analogous to E-values for unmeasured confounding. It assumes expectancy adds a fixed bias to the drug-placebo difference (shifting group means without changing within-group variability). The standard error is held constant because it reflects the trial’s precision, not the true effect size. These are simplifying assumptions; the real mechanics are almost certainly messier.↩︎
Goodwin himself cited 3 MADRS points as “a threshold for clinical significance” on the Compass results call. An alternative TRD-specific threshold of 6 points, derived from esketamine trial data, would be far more stringent—the Phase 2b result barely clears it even at face value. The Phase 3 results have even less room: Compass reported effect sizes of 3.6 points (COMP005) and 3.8 points (COMP006)—roughly half the Phase 2b and already hovering near the MCID threshold at face value. Full Phase 3 results with confidence intervals have not yet been published, but when they are, the same sensitivity logic will apply with much less margin.↩︎
Loewinger et al. also distinguish between belief about arm (which treatment the participant thinks they received) and expectancy (whether they expect to improve), arguing these are related but separable constructs with different causal roles. Both Compass trials used remote, centralized MADRS raters who were blinded to assignment, which addresses rater-level bias but not participant-level expectancy.↩︎